
分析のためのデータ加工処理では、特定の条件で行レコードの重複を除くといった処理をよく行います。
例えば、更新日付を持っているお客様属性情報からお客様毎に日付が一番新しいレコードを取得する処理、複数の契約情報から契約期間が一番長いレコードを取得する処理など、分析業務の中では様々なケースでレコードの重複を除く処理が必要となります。
Snowflakeでレコードの重複を除く処理を記述する場合、SQLのGroup by句を使う方法、Over句を使う方法の2つの方法があります。
Over句はGroup by句より読みやすく、簡潔に処理を記述することができるので、分析業務を行う方にはOver句を使うことをお薦めします。
分析業務は、新しい仮説を生み出しデータに変更を加えることも多いので、読みやすく、修正しやすいプログラムにすることは重要なポイントです。
私自身、Over句を知ってからは、レコード重複を除く処理にはOver句しか使っていません。
この記事では、SnowflakeのGroup by句、Over句を使って、レコードの重複を除く方法を説明します。
事例・テストデータについて
“A”から”E” 5人のお客様に対して、更新履歴をもったデータ(キーは更新日)を使い、お客様毎に更新日が一番新しいレコードのみ残す処理を考えます。
まず、今回の検証で利用するテストデータを作成するSQLは以下になります。
create or replace temporary table "テストデータ" as
select 'A' as "顧客ID" , '20240101' as "更新日" union all
select 'A' as "顧客ID" , '20240201' as "更新日" union all
select 'A' as "顧客ID" , '20240301' as "更新日" union all
select 'B' as "顧客ID" , '20240201' as "更新日" union all
select 'B' as "顧客ID" , '20240401' as "更新日" union all
select 'C' as "顧客ID" , '20240101' as "更新日" union all
select 'D' as "顧客ID" , '20240501' as "更新日" union all
select 'E' as "顧客ID" , '20240601' as "更新日" union all
select 'E' as "顧客ID" , '20240701' as "更新日" ;上記を実行すると9行のレコードが作成されます。
Group by句 を使った重複レコードを除く方法
SQLを勉強した方であれば、まず思いつくのが、group by句を使った方法です。
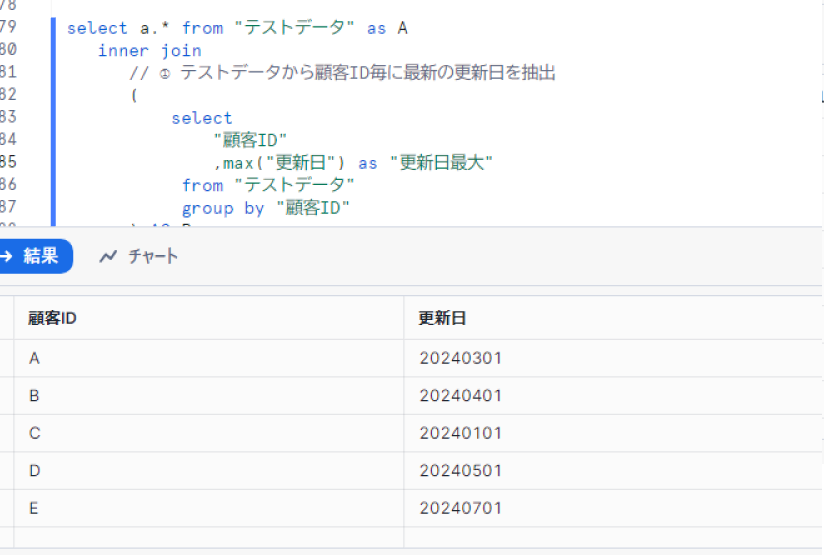
「テストデータ」から「顧客ID」毎に最新の「更新日」を保持するリストを作った上で、そのリストと「テストデータ」を顧客IDと更新日で結合し、対象のレコードを抽出します。
SQLは以下になります。
select a.* from "テストデータ" as A
inner join
// ① テストデータから顧客ID毎に最新の更新日を抽出
(
select
"顧客ID"
,max("更新日") as "更新日最大"
from "テストデータ"
group by "顧客ID"
) AS B
// ②テストデータ と ①のデータを
on A."顧客ID"=B."顧客ID" and a."更新日"=b."更新日最大"①の部分で、「顧客ID」毎に最新の「更新日」を保持するリストを作成し、②の部分でテストデータとリストを紐付けています。
この方法の課題は、SQLが読みづらい点、項目名の変更や追加といった修正を行うする場合に色々な箇所(Select句、Group by 句、on 句)を書き換える必要がある点になります。
このような記述箇所が10個も20個もあったら、読んで理解するだけで大変ですし、間違わずに修正するのも大変ですよね。
SQLの実行結果は以下となります。
Over句 を使った重複レコードを除く方法
分析屋としてレコード重複を除く方法の本命は、このOver句を使った方法です。
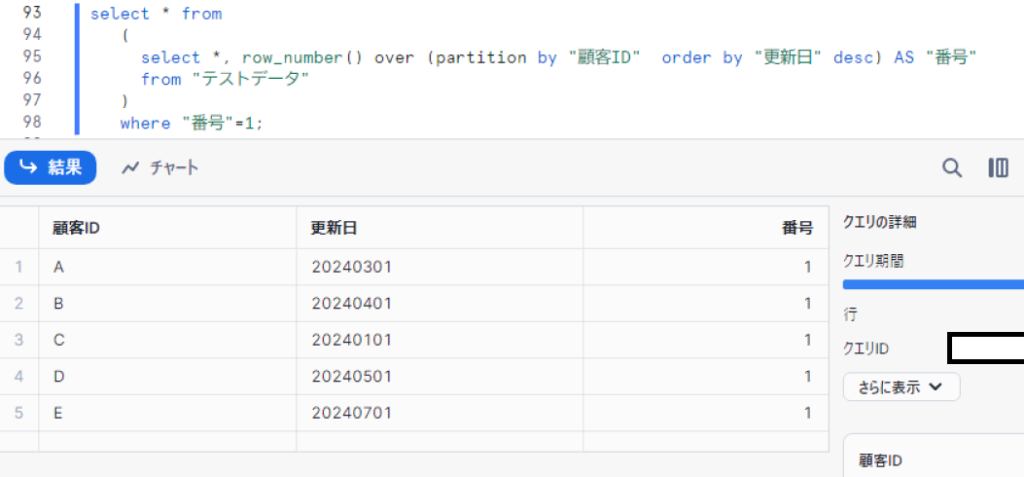
「テストデータ」を、 partition by で指定した顧客ID毎に order by で指定した項目順に並び変えて、1から順番に番号を付与、番号1のレコードを抽出します。
SQLは以下になります。
select * from
(
select *, row_number() over (partition by "顧客ID" order by "更新日" desc) AS "番号"
from "テストデータ"
)
where "番号"=1;特徴は、何と言っても、SQLがシンプルなことです。
項目(顧客ID、更新日)の指定箇所が1か所しかないため、ぱっと見で仕様を理解しやすく、項目名の変更や追加も容易に可能です。
SQLの実行結果は以下となります。
まとめ
Snowflakeでレコード重複を除く方法としては、SQLのOver句とGroup by句を使った方法があります。
分析業務に利用する場合、読みやすく、修正もしやすいといった点で、Over句の使用をお薦めします。
また、Over句を使った方法は、分析ツールSASにおけるレコード重複を除く方法と考え方が似ており、SASを使っていた方であれば理解しやすいです。
参考)SASツールにおけるレコード重複を除く方法
参考として、分析の定番ツールSASにおけるレコード重複を除く方法を記載します。
Sasプログラムは以下の通りです。
proc sort data=テストデータ ;by 顧客ID descending 更新日;run;
proc sort data=テストデータ nodupkey; by 顧客ID;run;SASで重複を除く処理は、2つのSTEPで実現します。
最初のSTEPでデータを顧客IDと更新日でソートした上で、次のSTEPで顧客ID毎に最初に出現したレコードのみ残すといった処理となります。
SQLのOver句と同じく、分かりやすい記述です。


コメント